![[ PART 6 ] Create a Twitter clone with GraphQL, Typescript, and React ( Adding Tweet )](https://cdn.hashnode.com/res/hashnode/image/upload/v1680264727298/a3815874-dd5a-4dc1-af52-b6a6e86acdfe.jpeg?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)
[ PART 6 ] Create a Twitter clone with GraphQL, Typescript, and React ( Adding Tweet )


Table of contents


No headings in the article.
Hi everyone! Let's start working on the tweets ;)
Link to the database diagram: Twitter DbDiagram
I start by creating the migration:
knex migrate:make add_tweets_table -x ts
import * as Knex from 'knex'
export async function up(knex: Knex): Promise<void> {
return knex.schema.createTable('tweets', (t) => {
t.increments('id')
t.text('body').notNullable()
t.integer('user_id').unsigned().notNullable()
t.integer('parent_id').unsigned()
t.enum('visibility', ['public', 'followers']).defaultTo('public')
t.enum('type', ['tweet', 'retweet', 'comment']).defaultTo('tweet')
t.timestamps(false, true)
t.foreign('user_id').references('id').inTable('users').onDelete('CASCADE')
t.foreign('parent_id')
.references('id')
.inTable('tweets')
.onDelete('CASCADE')
})
}
export async function down(knex: Knex): Promise<void> {
return knex.raw('DROP TABLE tweets CASCADE')
}
knex migrate:latest
To be able to work more easily, I will also add tweets to the database. For this, I will add the faker library:
yarn add -D faker
yarn add -D @types/faker
knex seed:make seed -x ts
*src/db/seeds/seed.ts
import * as Knex from 'knex'
import faker from 'faker'
import argon2 from 'argon2'
import User from '../../entities/User'
export async function seed(knex: Knex): Promise<void> {
await knex('users').del()
await knex('tweets').del()
for (let user of await createUsers()) {
const [insertedUser] = await knex('users').insert(user).returning('*')
const tweetsToInsert = await createTweets(insertedUser)
await knex('tweets').insert(tweetsToInsert)
}
}
const createUsers = async () => {
let users = []
const hash = await argon2.hash('password')
for (let i = 0; i < 10; i++) {
users.push({
username: faker.internet.userName(),
display_name: faker.name.firstName(),
email: faker.internet.email(),
avatar: faker.internet.avatar(),
password: hash,
})
}
return users
}
const createTweets = async (user: User) => {
let tweets = []
for (let i = 0; i < 20; i++) {
tweets.push({
body: faker.lorem.sentence(),
type: 'tweet',
user_id: user.id,
visibility: faker.random.arrayElement(['public', 'followers']),
})
}
return tweets
}
knex seed:run
Our database now has some data we can have fun with ;)
First of all, let's create our Tweet entity.
src/entities/Tweet.ts
import { Field, ID, ObjectType } from 'type-graphql'
import User from './User'
@ObjectType()
class Tweet {
@Field((type) => ID)
id: number
@Field()
body: string
@Field()
visibility: string
@Field()
type: string
@Field()
user: User
user_id: number
@Field()
created_at: Date
@Field()
updated_at: Date
}
export default Tweet
Note that I have a user property that will allow us to retrieve the author of the tweet. I also have a user_id property that I don't expose. Given that we will necessarily retrieve the user with each tweet, I do not see the point of exposing the user_id. Then at worst, if I change my mind or I didn't think about something, it's easy to change ;).
Let's now work on the TweetResolver.
src/resolvers/TweetResolver.ts
import { Ctx, Query, Resolver } from 'type-graphql'
import Tweet from '../entities/Tweet'
import { MyContext } from '../types/types'
@Resolver()
class TweetResolver {
@Query(() => [Tweet])
async feed(@Ctx() ctx: MyContext) {
const { db } = ctx
const tweets = await db('tweets').limit(50)
return tweets
}
}
export default TweetResolver
To test, I simply retrieve all the tweets in the database. We'll see later for the logic (retrieving only the tweets of the people we follow, pagination, etc ...).
Let's not forget to add the resolver to our resolvers:
src/server.ts
export const schema = async () => {
return await buildSchema({
resolvers: [AuthResolver, TweetResolver],
authChecker: authChecker,
})
}
This is where we will start to encounter our first "problems" ;). If I run the query without getting the associated user, it works without any problem:
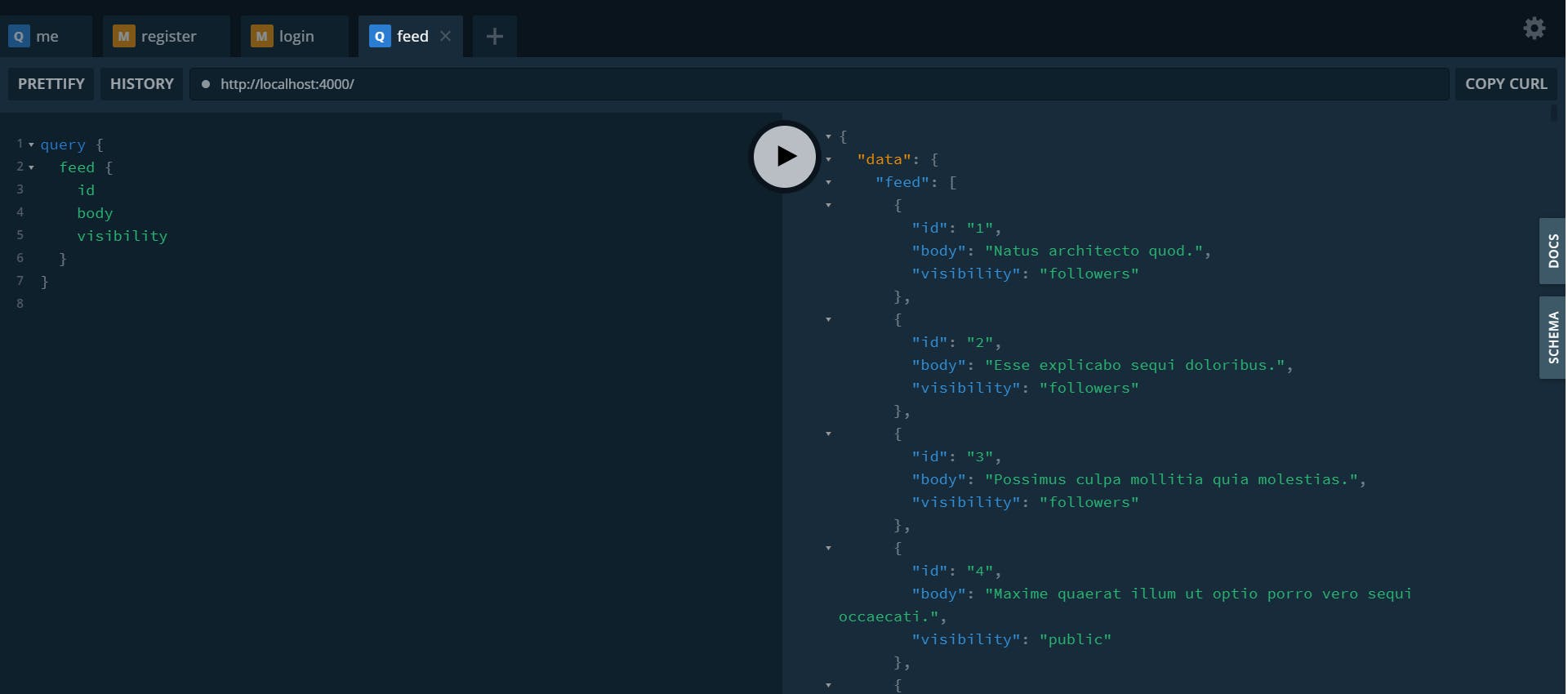
In my console, I have this SQL query:
SQL (8.414 ms) select * from "tweets"
Okay, let's try now by retrieving the associated user.
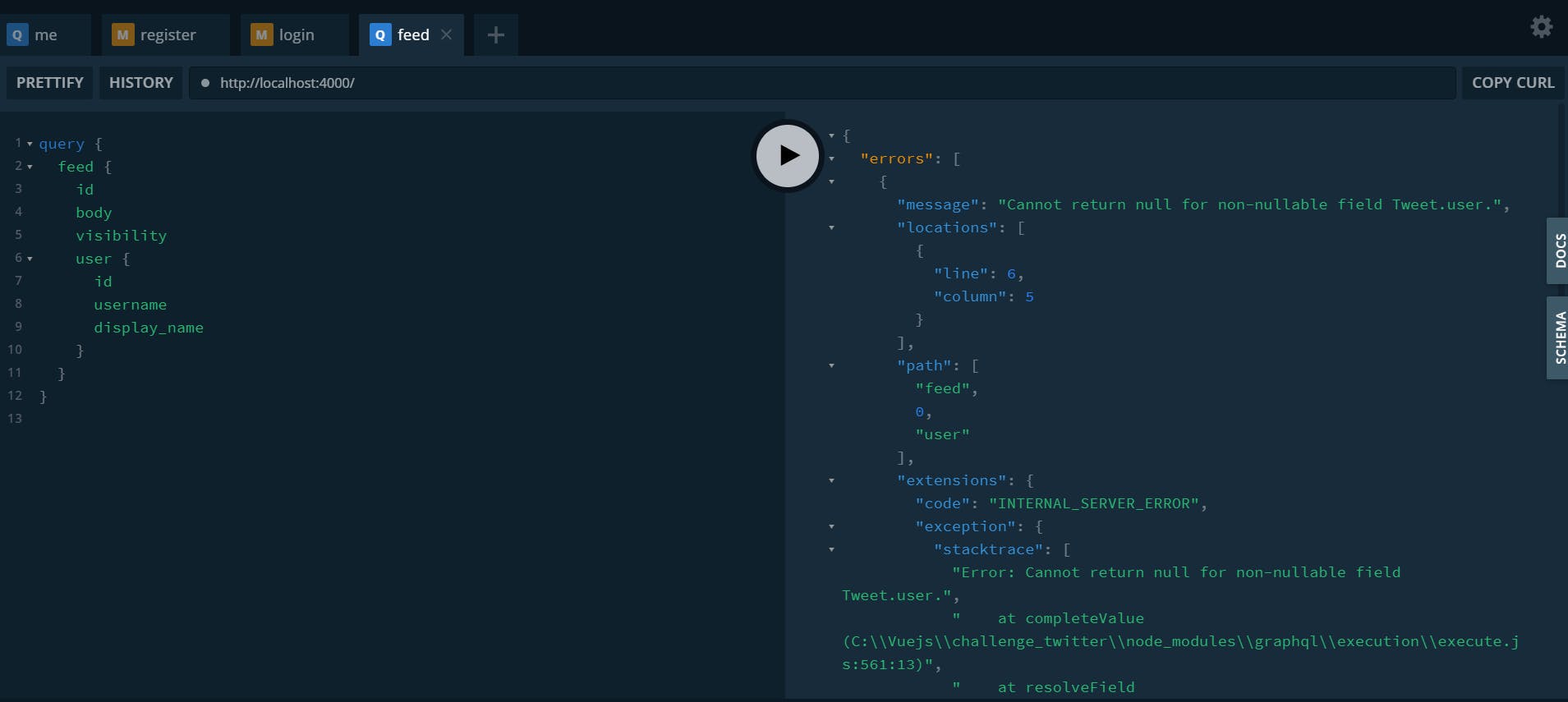
As expected, my SQL query does not return a user property, so this causes an error. To solve this, we have several choices. We could, for example, directly in our method feed, retrieve the users. Using Knex, which is a query builder, you have to write some code, but if you use an ORM, it can be done much more easily. For example with Laravel ( PHP ), you'll write something like this to have the same result: $tweets = Tweet::with('author')->get(); I haven't used any ORM yet in the Node.js universe but there is undoubtedly the same thing ;).
But for now with Knex.js:
@Query(() => [Tweet])
async feed(@Ctx() ctx: MyContext) {
const { db } = ctx
// Fetch the tweets
const tweets = await db('tweets').limit(50)
// Get the userIds from the tweets and remove duplicates.
// Array.from is used for the whereIn below ;)
const userIds = Array.from(new Set(tweets.map((t) => t.user_id)))
// Fetch the users needed
const users = await db('users').whereIn('id', userIds)
// Remap the tweets array to add the user property
return tweets.map((t) => {
return {
...t,
user: users.find((u) => u.id === t.user_id),
}
})
}
It works as expected ;).
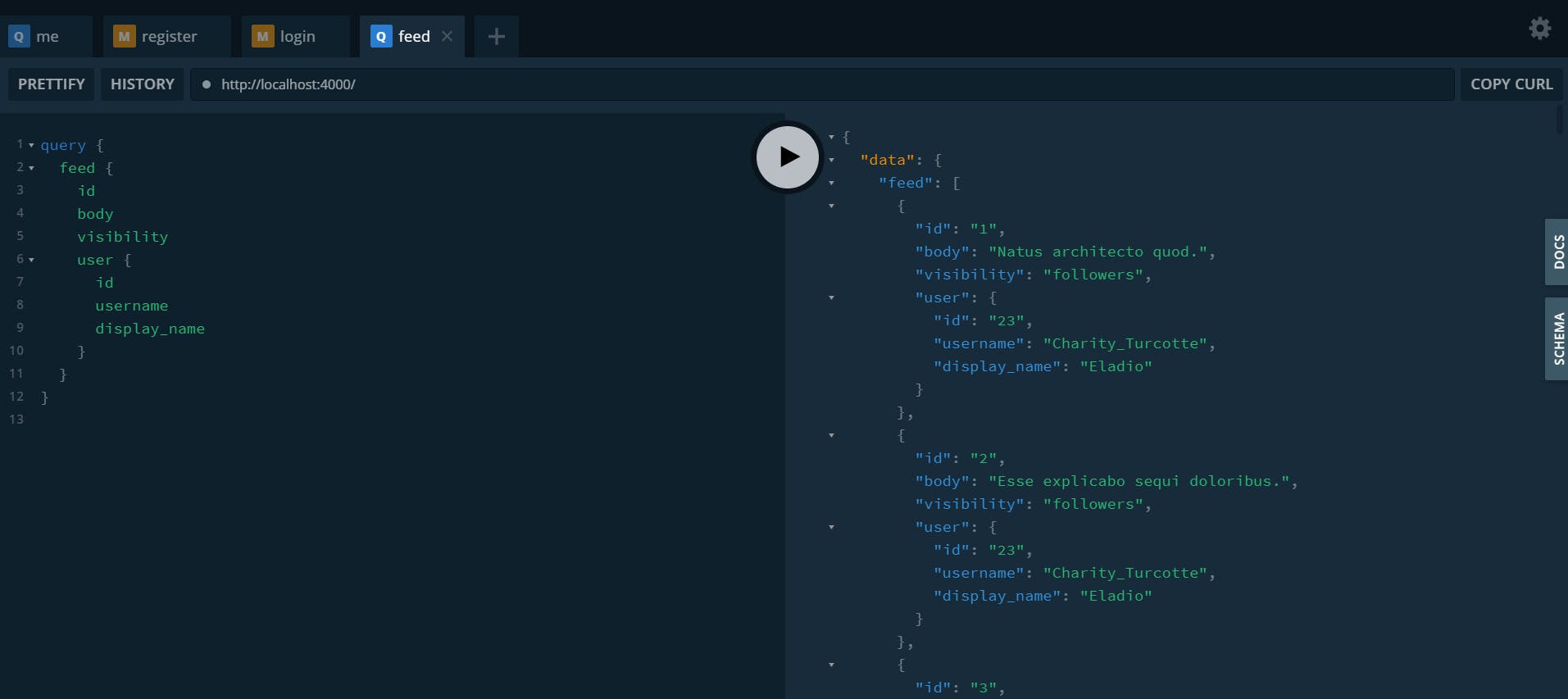
However, there is another way of proceeding that we will see right away ;)
We will use a @FieldResolver to tell it how to recover a user.
src/resolvers/TweetResolver.ts
import { Ctx, FieldResolver, Query, Resolver, Root } from 'type-graphql'
import Tweet from '../entities/Tweet'
import User from '../entities/User'
import { MyContext } from '../types/types'
@Resolver((of) => Tweet)
class TweetResolver {
@Query(() => [Tweet])
async feed(@Ctx() ctx: MyContext) {
const { db } = ctx
const tweets = await db('tweets').limit(50)
return tweets
}
@FieldResolver(() => User)
async user(@Root() tweet: Tweet, @Ctx() ctx: MyContext) {
const { db } = ctx
const [user] = await db('users').where('id', tweet.user_id)
return user
}
}
export default TweetResolver
However, if I launch my request again, it will work, but if I look at my logs, we will see a small problem ;)
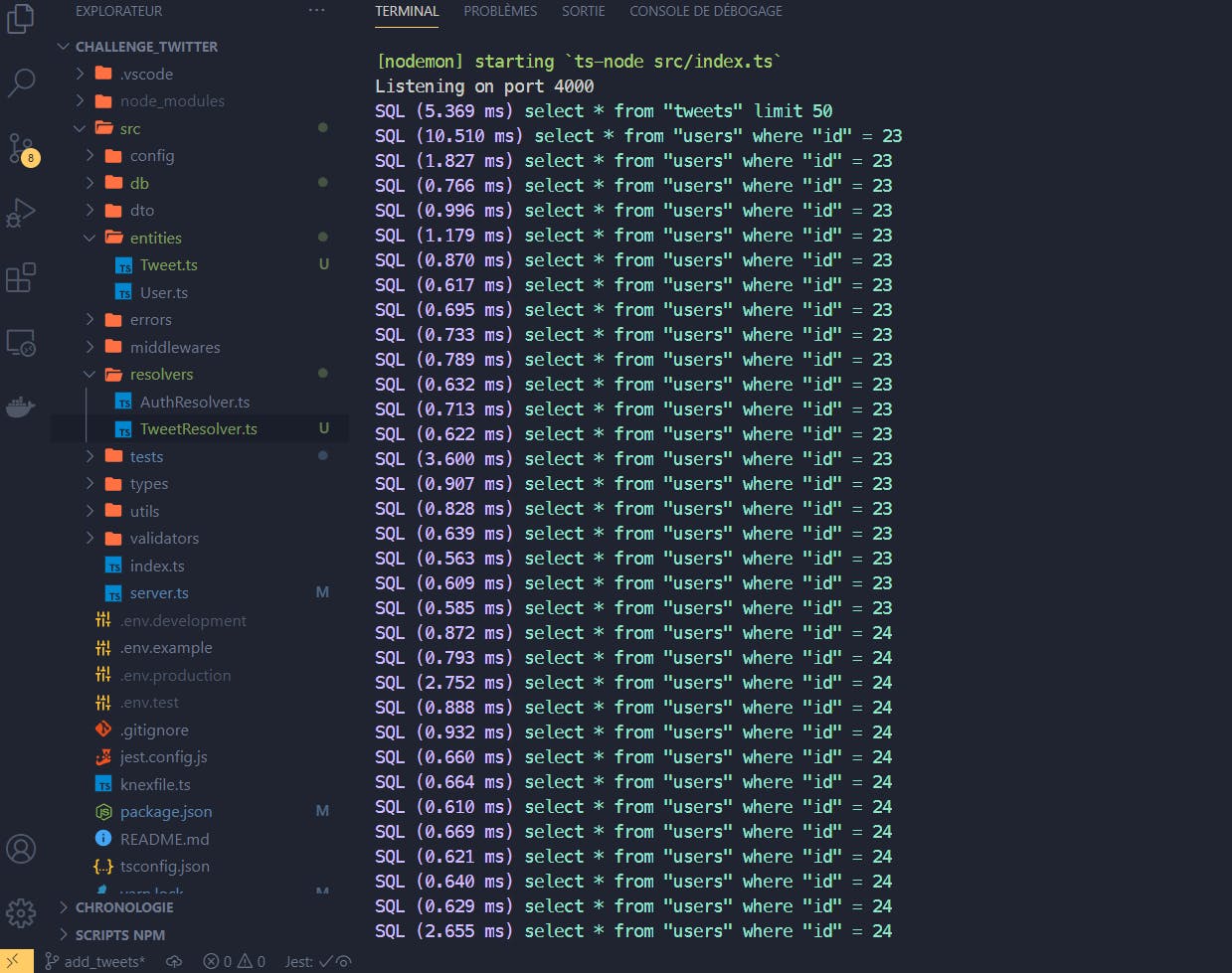
Indeed, it will make me a query for each Tweet to retrieve the user. Not great ;). To overcome this problem, we will use the dataloader library.
yarn add dataloader
Being also learning GraphQL, I'm still not sure how to structure my files regarding dataloaders. If you have any suggestions or repositories to propose, feel free to share them ;).
src/dataloaders/dataloaders.ts
import DataLoader from 'dataloader'
import db from '../db/connection'
import User from '../entities/User'
export const dataloaders = {
userDataloader: new DataLoader<number, any, unknown>(async (ids) => {
const users = await db('users').whereIn('id', ids)
return ids.map((id) => users.find((u) => u.id === id))
}),
}
The Dataloader receives the keys in parameters. From there, we will retrieve the users with a whereIn. All that remains is to map the ids to retrieve the corresponding user.
Then I add the dataloaders in our context to be able to access them:
src/server.ts
import { dataloaders } from './dataloaders/dataloaders'
export const defaultContext = ({ req, res }: any) => {
return {
req,
res,
db,
dataloaders,
}
}
All that's left to do is to update our @FieldResolver user.
src/resolvers/TweetResolver.ts
@FieldResolver(() => User)
async user(@Root() tweet: Tweet, @Ctx() ctx: MyContext) {
const {
db,
dataloaders: { userDataloader },
} = ctx
return await userDataloader.load(tweet.user_id)
}
If I launch the query, everything works again, and if I look at my console to check the SQL queries made:

We end up with a much more reasonable number of requests ;). On the other hand, since the dataloader caches the requests, you should not forget to clear the cache when you add a tweet for example. But we'll come back to this later.
I also added a test if you want to have a look ;).
src/tests/tweets.test.ts
import db from '../db/connection'
import { FEED } from './queries/tweets.queries'
import { testClient } from './setup'
describe('Tweets', () => {
beforeEach(async () => {
await db.migrate.rollback()
await db.migrate.latest()
await db.seed.run()
})
afterEach(async () => {
await db.migrate.rollback()
})
test('it should fetch the tweets with user', async () => {
const { query } = await testClient()
const res = await query({
query: FEED,
})
expect(res.data.feed[0]).toMatchSnapshot()
})
})
Well, I think it's enough for this article ;). See you in the next episode where we'll see how to insert tweets ;).
Bye and take care! :tropical_drink:
You learn 2-3 things and want to buy me a coffee ;)? buymeacoffee.com/ipscoding